Video Sources
To configure video-based object monitoring, add cameras to FindFace Multi, grouping them subject to their location.
Note
Privileges to create camera groups and cameras are managed in user’s permissions (see Role and User Management).
In this chapter:
Create Camera Group
Tip
A default preconfigured camera group is available in the system.
To create a group of cameras, do the following:
Navigate to the Settings tab. Click Camera Groups.
Click + Add new camera group.
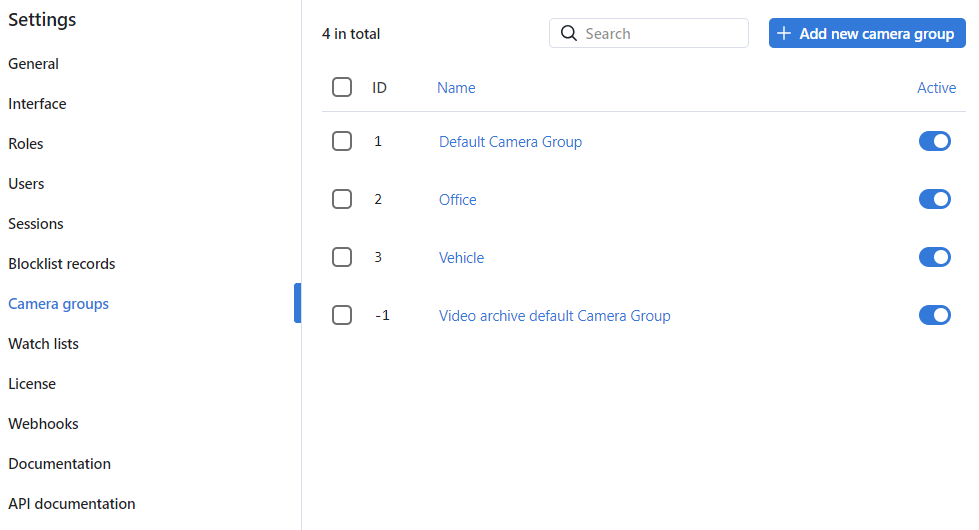
On the Information tab, specify the group name. Add a comment if needed.

If you want to allocate a certain
findface-video-workerinstance to process video streams from the group, create or select one or several allocation labels.Note
To complete the allocation, list the labels in the
findface-video-worker.yamlconfiguration file. See Allocate findface-video-worker to Camera Group for details.If you want to deduplicate events from cameras that belong to the same group, i.e. exclude coinciding events, select Deduplicate events with interval and specify the deduplication interval (interval between 2 consecutive checks for event uniqueness).
Warning
Use deduplication with extreme caution. If cameras within a group observe different scenes, some objects may be skipped. See Deduplicate Events for details.
By default, video from all camera groups is processed using the generic confidence threshold. To set an individual threshold for the camera group, select Confidence Threshold and specify the threshold value.
Important
The default generic confidence threshold is optimal for the majority of recognition cases. We do not recommend changing it on your own. Be sure to consult with our technical experts prior (support@ntechlab.com).
Click Save.
On the Permissions tab, assign privileges on the camera group, specifying which user roles are allowed to change/view the camera group settings.
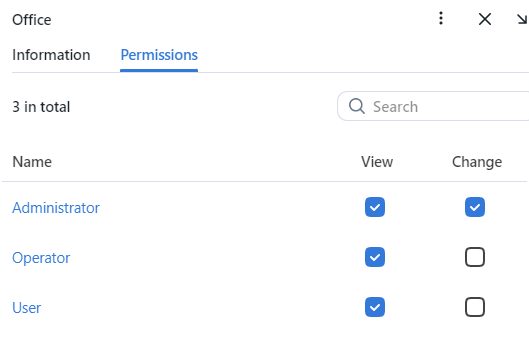
Click Save.
Add Camera
To add a camera, do the following:
Navigate to the Video Sources → Cameras.
Click + Add cameras or + Add.

On the Devices tab, enter the stream URL and click Next.

Enter the camera name.
Add the camera to a camera group.
Select detectors that you want to enable on this camera: faces, bodies, vehicles.

Click Add and configure. You will see additional tabs appear.
Select the camera on the list to open the processing configuration wizard. Set up the video processing parameters.
If the camera is ONVIF, select it from the list of detected devices to automatically load available settings and streams.

Video processing parameters
For each camera, you will be provided with complete statistics such as current session duration, the number of successfully posted objects, the number of objects processed with errors after the last job restart, the number of frame drops, and other data. To consult these data, click the camera and go to the Info tab.

On the General tab, you can change Camera Name, Camera group, or add Description. You can record video and enable liveness. Select detectors that you want to enable on this camera: faces, bodies, vehicles.

On the Advanced tab, fine-tune the camera:

If needed, change the video orientation.
Important
Be aware that the
findface-multi-legacyserver rotates the video using post-processing tools. It can negatively affect performance. Rotate the video via the camera functionality wherever possible.Timeout: Specify the timeout in milliseconds for posting detected objects.
Verify SSL certificate: Select to enable verification of the server SSL certificate when the object tracker posts objects to the server over https. Deselect the option if you use a self-signed certificate.
Retrieve timestamps from stream: Select to retrieve and post timestamps from the video stream. Deselect the option to post the current date and time.
Add to timestamps: Add the specified number of seconds to timestamps from the stream.
FFMPEG parameters: FFMPEG options for the video stream in the key-value format, for example, [“rtsp_transpotr=tcp”, “ss=00:20:00”].
Play speed limit: If less than zero, the speed is not limited. In other cases, the stream is read with the given
play_speed. Not applicable for live-streaming.Force input format: Pass FFMPEG format (mxg, flv, etc.) if it cannot be detected automatically.
Minimum motion intensity: Minimum motion intensity to be detected by the motion detector.
Read frames from source without drops: By default (false), if
findface-video-workerdoes not have enough resources to process all frames with objects, it drops some of them. If this option is active (true)findface-video-workerputs excessive frames on a waiting list to process them later. Set a variable to true when processing files as cameras.Process the stream once until the end or until the first error (single_pass): If true, disable restarting video processing upon error.
Router URL (router_url): IP address for posting detected objects to external video workers from
findface-video-worker. By default,'http://127.0.0.1'.
Specify the region of tracking within the camera field and region of interest (Zones). Click Save.

The region of tracking enables detecting and tracking faces/bodies and vehicles only inside a clipping rectangle. You can use this option to reduce the video object detector load. The region of interest enables posting objects detected only within its boundaries.
On the Faces, Bodies and Vehicles tabs, specify settings for each object type detector.

Size: Minimum object size in pixels to post and maximum object size in pixels to post.
Quality: The minimum quality of the face image for detection. The allowed range is from 0 to 1. The recommended reference value is 0.45, which corresponds to object images of satisfying quality. Do not change the default value without consulting with our technical experts (support@ntechlab.com).
JPEG quality: Full frame compression quality.
Full frame in PNG: Send full frames in PNG and not in JPEG as set by default. Do not enable this parameter without consulting with our technical experts (support@ntechlab.com) as it can affect the entire system functioning.
Overlap threshold: The percentage of overlap of bboxes between two serial frames so that these bboxes are considered as one track. The range of values is from 0 to 1. Do not change the default value without consulting with our technical experts (support@ntechlab.com).
Track maximum duration: The maximum approximate number of frames in a track, after which the track is forcefully completed. Enable it to forcefully terminate endless tracks, for example, tracks with faces from advertising media.
Forced termination interval: Terminate the track if no new object has been detected within the specified time (in seconds).
Send track history: Send array of bbox coordinates along with the event. May be applicable for external integrations to map the path of an object.
Crop full frame: Select to crop the full frame to the size of the ROT area before sending it for recognition. The size of the full frame will be equal to the size of ROT area.
Offline mode (overall_only): By default, the system uses the offline mode to process the video, i.e., it posts one snapshot of the best quality per track to save disk space. Disable it to receive more face snapshots if needed. If the offline mode is on, the parameters of the real-time mode are off.
Real-time mode parameters:
Note
These parameters are non-functional if the offline mode is on.
Interval: Time interval in seconds (integer or decimal) within which the object tracker picks up the best snapshot in the real-time mode.
Post first object immediately: Select to post the first object from a track immediately after it passes through the quality, size, and ROI filters, without waiting for the first
realtime_post_intervalto complete in real-time mode. Deselect the option to post the first object after the firstrealtime_post_intervalcompletes.Post track first frame: At the end of the track, the first frame of the track will be additionally sent complimentary to the overall frame of the track. May be applicable for external integrations.
Post in every interval: Select to post the best snapshot within each time interval (
realtime_post_interval) in real-time mode. Deselect the option to post the best snapshot only if its quality has improved comparing to the posted snapshot.Post track last frame: At the end of the track, the last frame of the track will be additionally sent complimentary to the overall frame of the track. May be applicable for external integrations.
Confidence threshold: A confidence threshold is used for matching the detected object with the internal entity object.
(Optional) On the GEO tab, specify the camera geographical location.

Disabled by default, the VMS cleanup settings tab allows you to configure video cleanup for a single camera. Follow this instruction Enable VMS Cleanup Settings in the UI to enable the tab in the web interface.

Custom VMS cleanup settings override the global ones for a single camera. The following custom VMS cleanup settings are available:
Clean up between tracks
Enable custom cleanup: enable custom clean up between tracks’ settings. By default, global settings are used.
Clean up between tracks: remove those intervals between tracks that do not contain recognition events.
Save tracks of events: save tracks of events for a selected object (face, body, or vehicle).
Keep events before and after: a video interval in seconds before and after a track with events that is kept along with the track.
Cleanup threshold: a minimum interval between tracks in seconds. If an interval between tracks is below the threshold, the video is not removed. A minimum allowed value for this field is 360 seconds.
Clean up between tracks from: time period (in days) during which the entire video archive is kept. After this period, the intervals between tracks will be cleaned up as configured in the settings. The value can be greater than or equal to zero.
Clean up archive
Enable custom cleanup: enable custom archive cleanup settings. By default, global settings are used.
Clean up archive: enable the entire video archive cleanup.
Archive cleanup age: a number of days the video archive is kept in the system. After that period, the video archive is removed.
Clicking on Display global settings will display global VMS cleanup settings.
See also
Upload and Process Video File
To upload and process a video, do the following:
Navigate to the Video Sources → Uploads.
Click Upload files or Upload.
Specify a URL to the online storage, or select a file. Click Upload.

Designate a camera group to which the system will attribute the object recognition events from the video. The
Video archive default Camera Groupis perfect for this task. You can also create a new camera group with basic settings specifically for this video file. Select detectors that you want to enable on this video: faces, bodies, vehicles.
Click Add and configure. The video will be uploaded and shown in the source list.
Click the video on the list to open the processing configuration wizard. Specify parameters of video processing in the same way as for cameras.

(Optional) Select a camera within that camera group to tag the object recognition events from this video more precisely.
(Optional) Configure the timestamps for object recognition events.
On the list of video uploads, click three dots → Process to start object identification. You can view object identification events on the Events and Episodes tabs by filtering the list of events by the camera group/camera associated with the video.
External Detector
A camera object can also be used for integrating an External Detector.

If necessary, change the External detector name. Specify the Initial camera group and Description, enable liveness.

Monitor Camera Operation
To monitor the operation of cameras, navigate to the Cameras tab.

Camera statuses:
Green: the video stream is being processed without errors.
Yellow: the video stream is being processed for less than 30 seconds, or one or more errors occurred when posting an object.
Red: the video stream cannot be processed.
Grey: camera disabled.
Tip
You can configure the yellow and red statuses based on the portion of dropped frames and failed object postings. To do so, modify the following parameters in the /opt/findface-multi/configs/findface-multi-legacy/findface-multi-legacy.py configuration file:
sudo vi /opt/findface-multi/configs/findface-multi-legacy/findface-multi-legacy.py
FFSECURITY = {
...
# max camera frames_dropped percent
'MAX_CAMERA_DROPPED_FRAMES': {'yellow': 0.1, 'red': 0.3},
# max camera objects failed percent
'MAX_CAMERA_FAILED_OBJECTS': {'yellow': 0.1, 'red': 0.3},
...
}
Restart all FindFace Multi containers.
cd /opt/findface-multi/
sudo docker-compose restart
Each created camera is associated with a so-called job, a video processing task that contains configuration settings and stream data and is assigned to findface-video-worker. This task can be restarted.
To restart a job, click Restart. In this case, the number of errors will be reset to 0.

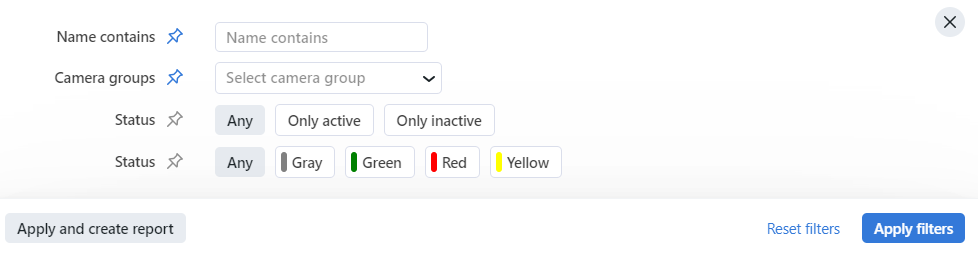
If there are numerous cameras in the system, use the following filters:
Name contains,
Camera groups,
Activity Status (Any / Only active / Only inactive),
Status of operation (Any / Gray / Green / Read / Yellow).